from d2l import torch as d2l
import numpy as np
import os
import pandas as pd
import random
import torchDataset statistics
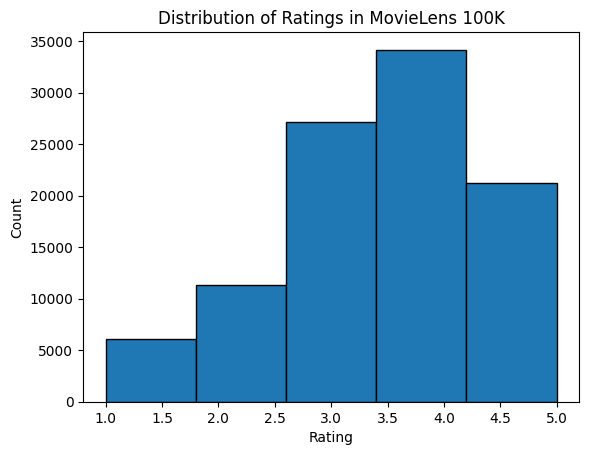
Sparsity calculation, rating distribution histogram — the two most informative diagnostics for a recommender dataset:
data, num_users, num_items = read_data_ml100k()
sparsity = 1 - len(data) / (num_users * num_items)
print(f'number of users: {num_users}, number of items: {num_items}')
print(f'matrix sparsity: {sparsity:f}')
print(data.head(5))number of users: 943, number of items: 1682
matrix sparsity: 0.936953
user_id item_id rating timestamp
0 196 242 3 881250949
1 186 302 3 891717742
2 22 377 1 878887116
3 244 51 2 880606923
4 166 346 1 886397596d2l.plt.hist(data['rating'], bins=5, ec='black')
d2l.plt.xlabel('Rating')
d2l.plt.ylabel('Count')
d2l.plt.title('Distribution of Ratings in MovieLens 100K')
d2l.plt.show()