GPUs are fast; Python is slow. If every tensor op had to wait for the GPU before Python proceeds to the next line, GPU utilization would be terrible.
The fix: deep-learning frameworks run asynchronously. The Python frontend dispatches an op (returns immediately) and the C++/CUDA backend queues it on a stream. Subsequent ops join the queue. The CPU and GPU work in parallel, and synchronization happens implicitly when you actually need a value (e.g. .numpy(), printing, conversion).
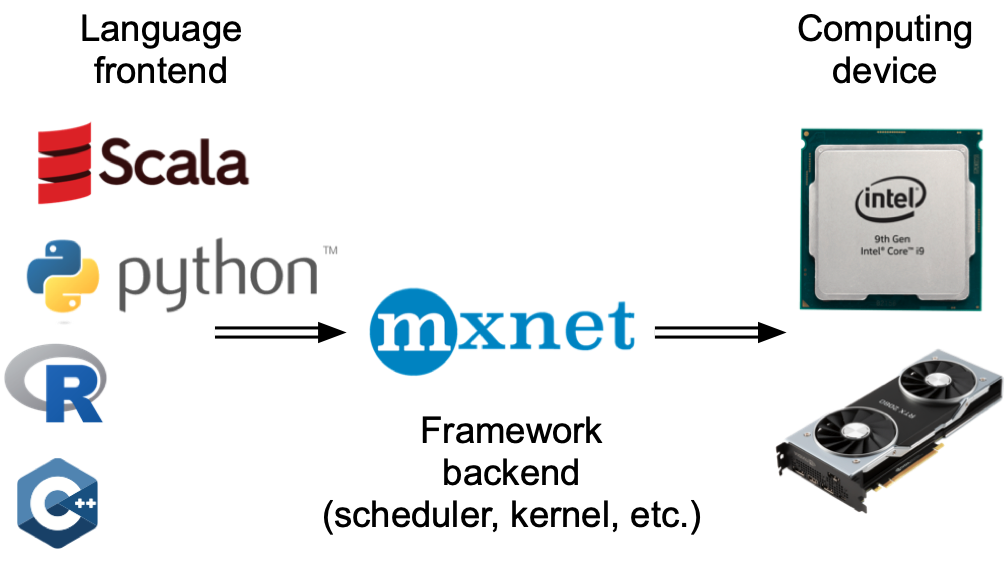
Programming language frontends and DL framework backends.
This deck shows how to measure async behavior, where it backfires, and how to write code that benefits from it.
Asynchrony in action
Time the same computation in pure NumPy vs the framework. NumPy is synchronous; the framework op returns immediately and the GPU runs in the background:
from d2l import torch as d2limport numpy, os, subprocessimport torchfrom torch import nn
# Warmup for GPU computationdevice = d2l.try_gpu()a = torch.randn(size=(1000, 1000), device=device)b = torch.mm(a, a)with d2l.Benchmark('numpy'):for _ inrange(10): a = numpy.random.normal(size=(1000, 1000)) b = numpy.dot(a, a)with d2l.Benchmark('torch'):for _ inrange(10): a = torch.randn(size=(1000, 1000), device=device) b = torch.mm(a, a)
numpy: 0.3747 sec
torch: 0.0007 sec
Asynchrony (cont.)
with d2l.Benchmark():for _ inrange(10): a = torch.randn(size=(1000, 1000), device=device) b = torch.mm(a, a) torch.cuda.synchronize(device)
Done: 0.0011 sec
x = torch.ones((1, 2), device=device)y = torch.ones((1, 2), device=device)z = x * y +2z
tensor([[3., 3.]], device='cuda:0')
The small dispatch time is not the real compute time until a synchronization point forces Python to wait for the backend queue to drain.
The dependency graph
The backend tracks dependencies between queued ops; ops without dependencies can run in parallel on different streams:
Backend tracks dependencies between graph nodes.
Frontend ↔︎ backend
Python frontend hands ops to a C++/CUDA backend; CUDA stream runs them asynchronously.
Barriers
Anything that needs a value forces a barrier — Python waits until the GPU catches up. Common offenders: printing intermediate values, .item(), .numpy(), control flow based on a tensor value:
Improving throughput
Avoid unnecessary barriers. Don’t print(loss) inside the training loop unless you need it. Don’t .cpu().numpy() mid-batch. Save metrics to a list of tensors and reduce later:
Recap
Frontend dispatches ops; backend queues and executes asynchronously. CPU and GPU overlap.
Synchronization is implicit on .item(), .numpy(), printing, conversion to NumPy.
Reading values mid-loop forces barriers and stalls the pipeline. Buffer metrics; reduce at epoch boundaries.
TF needs @tf.function to actually be async; PyTorch and MXNet are async by default.