%matplotlib inline
from d2l import mxnet as d2l
from mxnet import gluon, autograd, init, np, npx
from mxnet.gluon import nn
import pandas as pd
npx.set_np()Kaggle in 30 seconds
The competition
Kaggle hosts open ML competitions. Download the train and test CSVs, train locally, upload predictions, get scored on a held-out slice of the test set.
A public/private split on the test labels stops competitors from overfitting the leaderboard.
The House Prices competition page
The competition
The data is generic on purpose: no images, audio, or sequences, just a spreadsheet of house attributes and one price column.
That makes it the perfect first capstone, the whole job is the pipeline around the model.
K-fold cross-validation
Model selection
With ~1500 rows, one 80/20 split is noisy. Split the data into K folds; train K times, each time holding out a different fold; average the K validation scores.
Costs K\times the compute, buys a far steadier estimate, and the same loop supports hyperparameter search. Fit preprocessing anew inside each training fold; otherwise the held-out fold leaks into the model pipeline.

Submit: ensemble the folds, write the CSV
Submitting
Average the K log-price predictions, exponentiate, submit:
preds = [model(d2l.tensor(test.values.astype(float), dtype=d2l.float32))
for model, test in models]
# Average the K log-price predictions in log space, then exponentiate.
ensemble_preds = d2l.exp(d2l.reduce_mean(d2l.concat(preds, 1), 1))
submission = pd.DataFrame({'Id':data.raw_val.Id,
'SalePrice':d2l.numpy(ensemble_preds)})
submission.to_csv('submission.csv', index=False)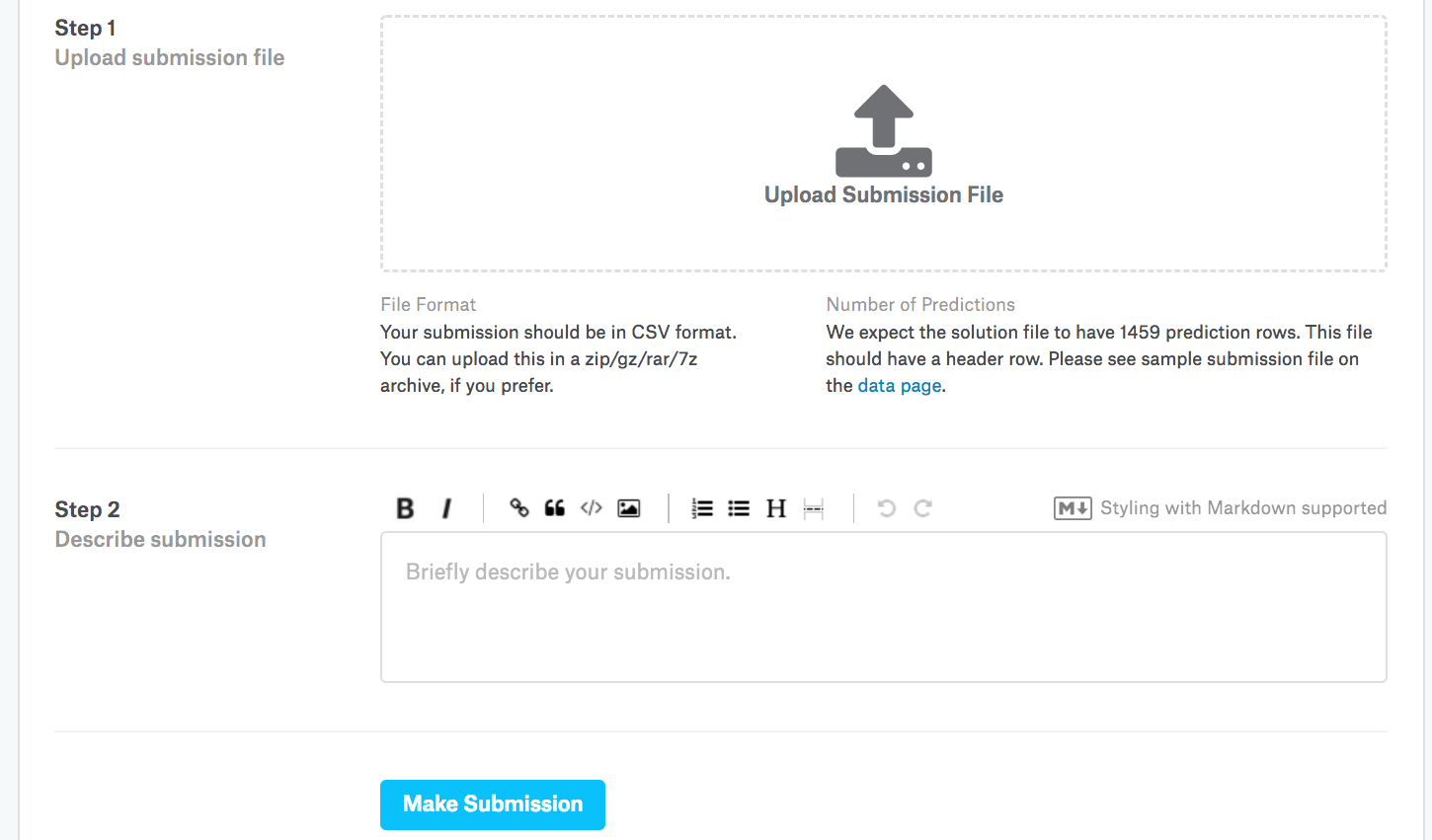
The log-space mean averages predictions in the space where RMSLE measures error; exponentiating makes it a geometric mean in price space. This does not guarantee an improvement. The CV score measured a single fold model; refitting on all data is the more direct alternative to this fold ensembling.